
吃豆子的wayne
Fri, 24th January 2020Edit on Github豆子算法
问题提出
2013年2月KeyTo9_Fans提出了wayne吃豆子问题:
假设有一条长度为的线段,左端点是,右端点是。
线段上有个豆子,wayne在这条线段上移动。
下图是一个的例子:

一旦wayne的坐标与某个豆子的坐标相等,wayne就会把这个豆子吃掉。
一旦wayne把一个豆子吃掉,一个新的豆子就会立即出现在区间中均匀分布的一个随机的点上。
wayne的移动速度是每秒单位长度。
wayne可以随时改变移动方向。
wayne总是采取最佳策略,使得吃豆子的平均速率最大。
于是当时,wayne吃豆子的平均速率是个每秒;
当时,wayne吃豆子的平均速率是个每秒。
问题:当时,wayne吃豆子的平均速率是多少?
问题:当时,wayne吃豆子的平均速率是多少?
问题:当时,wayne吃豆子的平均速率是多少?:lol
初步展开
wayne认为:
问题转化为求 的期望值, 在内均匀分布, 并且猜测答案为.
KeyTo9_Fans指出, 问题没有这么简单:
当然没问题咯,豆子在哪边wayne就往哪边跑。
可是当时就没那么简单了,
wayne经常要思考“到底先吃哪边的豆子才能使得吃豆子的平均速率最大呢?”
如下图所示:

如果wayne总是吃最近的那个豆子,
那么当时,模拟到个豆子,结果是……
wayne吃豆子的平均速率是个每秒。
可是wayne绝顶聪明,不一定总是吃最近的那个豆子,
所以当时,wayne吃豆子的平均速率要大于个每秒。
具体大多少,就得知道wayne采取的最佳策略是什么了_
并且Fans继续解释进一步题目中要求:
任何时候都有个豆子存在。
这是因为:
“一旦wayne把一个豆子吃掉,一个新的豆子就会立即出现在区间中均匀分布的一个随机的点上。”
wayne最初的位置在哪里都不要紧。
这是因为wayne永远都在这条线段上移动。
当给定时间时,wayne吃豆子的平均速率是,
其中是wayne在时间内所吃的豆子数。
所以无论wayne最初的位置在哪里,
的值都是一样的.
并且着重描述时的情况:
当时,wayne的策略可以用一个元的布尔函数来描述。
的输入是,,。
其中,和表示豆子的位置,表示wayne的位置。
的输出是一个方向,“左”或者“右”。
函数确定之后,wayne的策略也就确定了。
于是我们就可以对wayne的策略进行评价了。
评价的方法如下:
取一个足够大的,然后任取一个开始状态,
然后把wayne和豆子的位置作为函数的输入,
根据的输出来决定wayne下一步吃哪个豆子。
我们用来表示wayne在时间内所吃的豆子数。
越大,说明wayne的策略越好,越小,说明wayne的策略越差。
如果我们对所有可能的函数都模拟过一遍,我们就知道wayne的最佳策略是什么了。
最近策略不必然最优
KeyTo9_Fans通过实验的方法发现,当时,“总是吃最近的豆子”并不是最佳策略。
当两个豆子差不多近时,优先吃边上的豆子,可以吃得更快:lol

具体的策略函数如下:
如果Score Score ,那么,否则。
其中:
,(表示豆子离处越远越好,离wayne越近越好)
表示在的哪边就去哪边。
该策略吃豆子的平均速率是个每秒,比“总是吃最近的豆子”的策略好。
(楼“总是吃最近的豆子”的策略的速率只有个每秒)
wayne建议Score函数里面的参数可以替换成其它值再试验一下看看。
Fans经过试验,得出:
最佳参数,吃豆的速率是。
不同权函数试验
mathe认为:
其实k=2时,本质是求一个函数,如果那么选择左边,如果选择右边。同样k=n时是求一个将n个数映射到n-1个数的函数。
而给定选择函数,应该可以通过迭代得出的一个稳定的分布密度,也就是经过一次迭代后密度函数保持不变。然后计算这个密度函数下的平均速率,所以是一个带额外约束条件变分问题,只是k越大,表达式越复杂,很难计算。
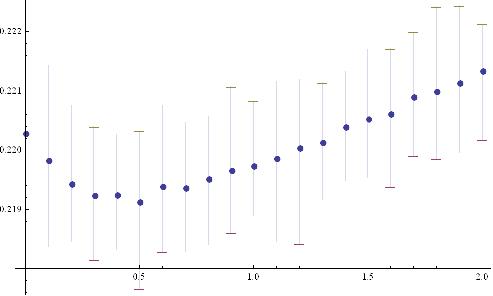
zgg__参考mathe的思路,尝试了一些函数g,最后还是选择了平均数,令gq(x1,x2)为x1、x2和这三个数的加权算数平均数,其权的比例为1:1:q,故。然后做了一点数据模拟,对每一个k,每次吃个豆,反复吃50次求平均、最大和最小(代码见下)。
g[x1_, x2_, k_] := (x1 + x2 + k/2)/(k + 2);
ks = {};
Do[ts = {};
Do[w = 0.5; t = 0; s1 = Random[]; s2 = Random[];
Do[If[s1 < s2, x1 = s1; x2 = s2, x1 = s2; x2 = s1;];
If[w < g[x1, x2, k], tt = Abs[w - x1]; w = x1; s1 = x2;,
tt = Abs[w - x2]; w = x2; s1 = x1;];
s2 = Random[]; t = (t n + tt)/(n + 1);, {n, 0, 100000}];
AppendTo[ts, t];, {50}];
AppendTo[ks, {{k, Mean[ts]}, {k, Min[ts]}, {k, Max[ts]}}];
Print[k];, {k, 0, 2, 0.1}];
ListPlot[Transpose[ks], Filling -> {1 -> {2}, 1 -> {3}},
PlotMarkers -> {" \[FilledCircle]", "\[LongDash]", "\[LongDash]"}] 结果如图,纵轴是吃每一个豆的平均时长,是lz说的吃豆速度的倒数,横轴是1/2的权重,当权重q=0,相当于吃最近的,当权重q很大时,相当于随便吃,即每次出现一个豆的情况(k=1)。此代码效率低,有空弄个好点的。
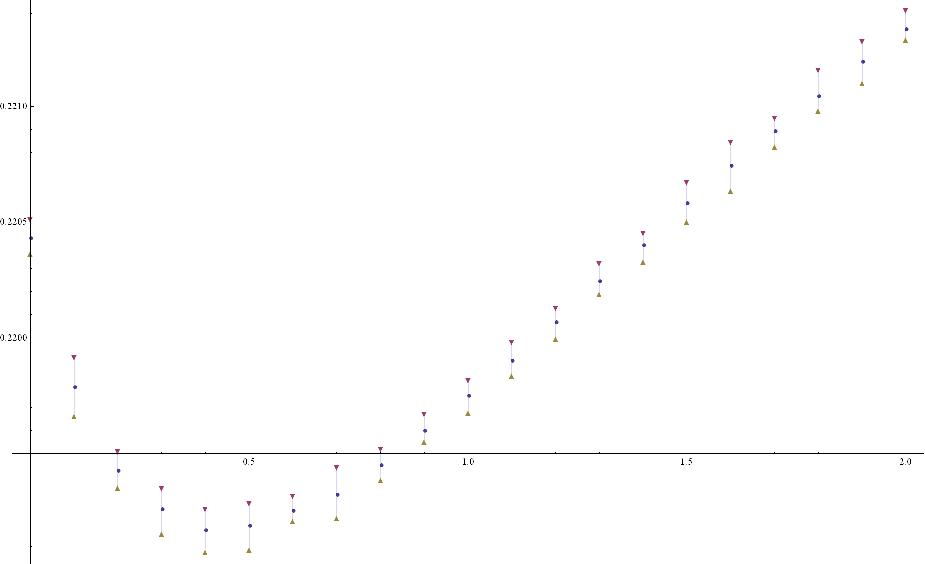
然后又计算了颗豆子吃10次,得到
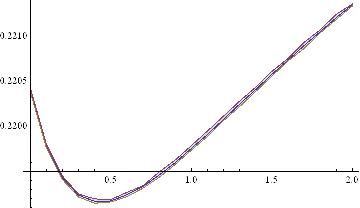
然后用写了段C代码并且将结果用Mathematica作图得到下图:
dianyancao也给出了他的一种策略:
使用如下策略得到的结果
p=0.38
t=0.218766
v1 = Abs[w - rightx] + p * Abs[leftx - xforecast];
v2 = Abs[w - leftx] + p * Abs[rightx - xforecast];
rightx位于w右边,leftx位于w左边,xforecast=1/2
根据v1和v2的大小关系,确定吃右边的豆子还是左边的豆子
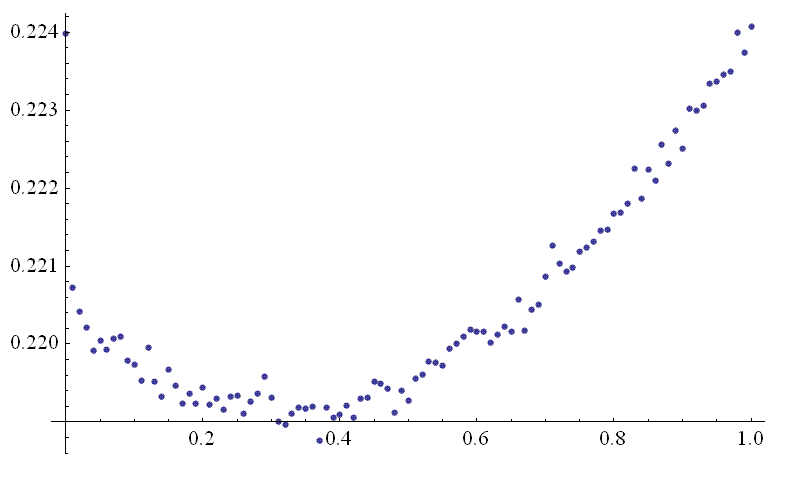
已经对应的Mathematica代码和结果图:
更多豆子的思考
无心人提议:
假设当前处在位置,豆子在两边各有, 个,相对密度分别是,
当前位置分割区间为2部分,相对有2个可选择移动方向
假设当前吃完一个豆子,下个豆子出现的时候总是早于wayne的思考的开始
假设wayne思考时间为0,
假设初始wayne处于0.5位置,且假设初始豆子先于wayne出现
策略1:总向当前豆子数最多的方向移动,如果相等,则向距离边界最短的方向移动,如果距离两边界也相等,则向密度最大方向移动,如果连密度都相等,则保持当前移动方向不变。。。
策略2:总向当前豆子密度最大的方向移动,如果密度相等,则向距离边界最短的方向移动,如果距离两边界也相等,则豆子最多方向移动,如果连豆子数都相等,则保持当前移动方向不变。
策略3:先右,或者先左,直到某方向没有豆子再转向,转向之后,即使身后出现新豆子也不回退
策略4:先右直到边界再转向,或者先左直到边界再转向
策略5:先吃左边然后马上转向右边,或者先吃右边然后马上转向左边
采用积分计算
mathe提议,k=2时设最优策略是g(a,b),也就是在豆子位置为,如果,选择位置的豆子,不然另外一个豆子。那么设稳定时豆子和wayne位置的密度分布函数为
记
对于,必然有,同样计算和情况都是两个函数和的形式。
然后再次代入K,F的定义得出它们的积分表达式,这样就可以变成一个两个变量的积分等式问题,如果用计算机计算,就可以比原问题少一个维数,从而大大降低计算量
zgg继续结合他的权函数,采用积分算式计算:
对k=2时情况的计算有了一点进展,呵呵。
假定函数fw是w吃完豆后的分布,f是w没吃的那个豆的分布,ft是新出的豆的分布(题目中ft=1),g是判据。当w刚吃完后,用w表示他的位置,用t表示剩下豆的位置,用x表示新出豆的位置,那么fw(c)是怎样的呢?w吃完豆后要落在c点,有两种可能性,一种是x恰好落在c并且w的位置满足吃x的条件,另一种是t恰好落在c并且w的位置满足吃t的条件。对于第一种可能,又有两种情况,一是x<t且w<g(x,t,p),另一是x>t且w>g(x,t,p)。对于第一种情况,有图中式1,剩下的三种同理,并且用字母x替换字母c,有图中式2,再同理可以计算f,有图中式3。把2式和3式相加,就可以得到fw=1了。
将fw=1代入2式,并且对x求2次导数,就可以得到微分方程了,如果限定g[x,t]=(x+t+p/2)/(p+2),那么方程为图中式4(用3式也是一样的)。这个方程是可解的,可以得到式5的结果(注:5式恰好是6式的二阶导数)。然后将5式f的结果代入7式就可以求出预期的吃豆时长了。7式只是依赖于p,当p为特殊值时是有符号解的,例如p=0时(w总去吃最近的豆),得到8式(0.218501)的结果,对7式进行数值计算,可以得到如下图的结果。呵呵。

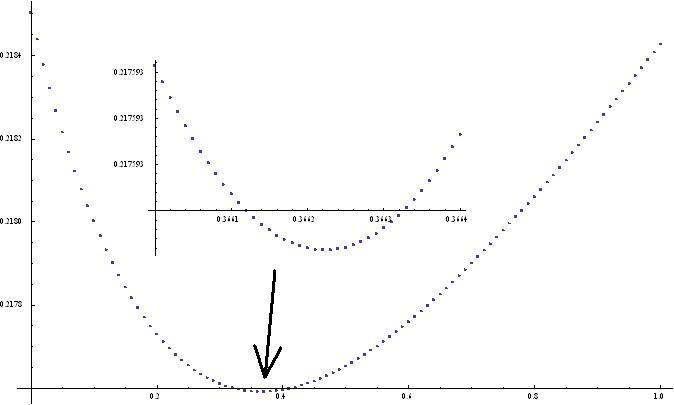
但是给出的结果好像有点问题,结果有点太好了。
mathe对最简单的权函数进行积分运算,分别给出了两个不同版本的Pari/gp代码: 代码1, 代码2.
最后得出:
(16:06) gp > getdist(2)
%17 = 0.2114583333333333333333333333
(16:07) gp > getdist(10)
%18 = 0.2203686807254583318975768873
(16:07) gp > getdist(20)
%19 = 0.2204074196271448826430741941
(16:07) gp > getdist(30)
%20 = 0.2204077318388700882261725891
(16:07) gp > getdist(40)
%21 = 0.2204077356077135199957228968
(16:07) gp > getdist(50)
%22 = 0.2204077356585942289207798388
(16:07) gp > getdist(60)
%23 = 0.2204077356593274980124179385
(16:07) gp > getdist(70)
%25 = 0.2204077356593385397246878697
(16:33) gp > getdist(99)
%1 = 0.2204077356593387142224517526
(16:10) gp > getdist(100)
%26 = 0.2204077356593387141426361209也就是我们可以得出时的高精度结果,也就是每秒4.537次,同Fans的模拟结果匹配.
k=2时结果总结
KeyTo9_Fans对多种策略进行模拟比较:
比较结果如下:
| 策略 | 结果 |
|---|---|
| 传说中的最佳策略 |
通过某种神奇的方法,
Fans终于得到了最佳策略下的平均吃豆时长,
为,
但该策略具体是什么还不知道。
Fans将该结果列在了上表的最后一行,
可以看到目前已知的最好的策略的平均吃豆时长已经与最佳策略的平均吃豆时长很接近了。
于是,楼主的第问终于有一个近似的答案了:
当时,wayne吃豆子的平均速率是个每秒。
为了展示吃个豆子的最佳策略,
Fans把这个问题做成了一个游戏。
解压上面附件后运行“bestcollect.exe”,就可以看到【传说中的最佳策略】了。
注意:
要把“solution.txt”和“bestcollect.exe”放在同一个文件夹里,不要分开了。
美中不足的是,我们只有【传说中的最佳策略】的一些离散的数据。
能否根据这些离散的数据找到函数的解析式呢?